程序调试经验
文中观点仅供参考!
阅读指南&摘要
本文是我从调试实践中沉淀出的一套方法,包含了设计、调试信息打印、看懂OJ报错信息等一系列经验,并附有可“即插即用”的自制调试工具代码。
本文较长,欢迎各位读者根据自己的需求做出选择:
- 思路错误?请重点阅读第一章,学习如何避免方向性错误。
- 看不懂OJ报错?请速查第二章的表格,快速定位问题类型。
- 想提升输出调试信息的效率?请参阅第三章,这里有万能print()和递归调试技巧。
- 陷入复杂逻辑?盯着输出发呆?相信第四章的纸上推演法能帮你破局。
- 想快速定位大段代码中的错误区间?第五章的“主动制造错误”法(探针法)或许可以提供一些思路。
转载请注明出处
第一章 设计先行,落“笔”有神
先绘制蓝图,再简洁地编写代码,同时加入注释辅助理解
- 设计思路:
-
好的设计是成功的开始,使用正确的思路才能写出优秀的代码。
-
对于算法题,特别是动态规划的算法题,一定要先想好思路,写出状态移方程
-
否则,花时间写完代码发现一场空,浪费了时间,还没解决问题。
-
一定要仔细阅读题目!!!很多时候出现错误,是因为我们没有正确理题目的意思。
-
例题:2250. 哼哼哈兮
- 这道题我最开始没有想好思路,忽略了“合成顺序也会影响最终结果”这个提示,没有考虑到两根单棒可以合成一根单棒,而这根棒可以作为一根单独的单棒参与后续合成,进而误以为是背包DP,花了几十分钟写代码得了0分。
- 后来,我重新仔细阅读题目,自己按照样例推导了一下,终于发现了我最开始想法的错误之处,发现是区间DP,重构代码后一下就100分了。
- 这个故事告诉我们:理解题意很重要,审题的时候千万不能急躁。
-
例题:2609. 森林冰火人
- 这是一道含有门和钥匙的双人走迷宫的问题。我最开始想使用DFS, 使用多步决策的思路来解决问题。后来,我从下午一点写代码,写到下午六点才勉强写出一个解决双人走不含门的迷宫的代码(中间做了很多调试,具体会在4介绍)。
- 后来,我迫不得已询问AI,他和我说可以用BFS。我自己在B站搜索视频学习了这个算法,发现这个算法对于解决寻路问题很有用。出于种种原因,笔者写这个总结的时候还没有尝试BFS,不过我相信使用BFS将会很快解决问题。
- 这个故事告诉我们:很多时候我们调试了很久都没发现问题,也许是因为我们最开始就选择了一条错误而复杂的道路。这充分说明了顶层设计的重要性。当一个代码实在很难调通的时候,强烈建议重构写代码。
-
代码编写:
-
编写代码建议遵循固定的范式,把一个完整的程序拆成了几块,更方便定位查出问题的模块,程序框架也会很清晰。
-
写程序就像“拼积木”,要有函数思想,对于重复使用的代码使用函数封装起来。它有下面三个好处:
- 方便我们建立清晰的逻辑框架,发现程序问题
- 减少代码量,提高开发速度
- 方便我们建立自己的代码库,写好一个函数,之后涉及相关思路的题都可以直接copy and paste已经写好的代码。
-
变量名的命名一定要有其实际含义,不建议用中文拼音对变量命名。使用“蛇形命名法”(如
previous_sum)或者“驼峰命名法”(如PreviousSum)。- 我常用的代码框架:
#include <iostream> #include <vector> using namespace std; //这两个变量在本文的 3 会介绍 bool DEBUG=1; bool GENERATE=0; //全局变量 int N=xxx; vector<int> XXX; // 以下为调试专用函数,具体会在 3 介绍 // 递归终止函数 void print_impl() { cout << endl; } <template>... void execute(){...} void input(){...} //在写和读取文件相关的题的时候很有用 void output(){...} //用于格式化调试数据,具体会在 3 介绍 void generate(){...} void debugger(){...} int main(){ if(DEBUG) debugger(); else input(); if(GENERATE) generate(); execute(); output(); return 0; }
-
-
数据结构
- 不要使用不熟悉的方法,也不要使用复杂的数据结构。用自己熟悉的数据结构可以迅速搭建代码,也不容易出错。
- 建议多用
vector和string,这些数据结构有完善的库函数支持 - 不建议用链表或者原生数组,因为这些数据结构需要手动管理内存。
- 例题:2373. 环形网络
- 这道题我使用链表完成,由于链表管理需要处理各种指针关系,很容易出现野指针和越界访问;同时,链表不能使用库函数的二分查找和排序,需要手动编写比较基础的增删差改的代码。最后,我花了一个半小时才把代码调通。
- 代码写完之后,我思考了一下,发现这道题直接用
vector可以更快完成任务,也不容易出现数组越界的问题。 - 这个故事告诉我们:要选择合适的数据结构,不建议使用原始数组或链表,不然前人开发
vector的意义在哪里呢?
-
注释编写
-
在合适的地方加入注释。一般建议在函数内的特定作用的代码前加入注释,因为函数内的代码块不像函数 一样有函数名提示这段代码的作用。
-
为代码块添加注释,可以帮助我们建立清晰的逻辑思路;更重要的是,它可以帮助我们一段时间后回看代码的时候不被代码绕晕。
-
人集中注意力只能专注局部的问题,同时人的记忆也是有限的。当我们把其中某个小的bug改好之后,如果不加入注释,就需要花费时间去重新理解之前写的其他代码。当我们调程序的时候,往往比较“晕”;如果这时候再来看一堆不加注释的代码,就会变得更“晕”,效率自然就下来了。
-
这里放一段我们老师写的跳马问题的代码作为示例:
// 第step步,从高度height开始,继续下楼 void Try(int height, int step) { // 递归中止条件:到达楼梯底层 if (height == 0) { num ++; cout << num << ": "; for (int i = 0; i < step; i++) cout << path[i] << ' '; cout << endl; return; } // 依次尝试不同的下楼步数(循环变量i是可能的步数) for (int i = 1; i <= 3; i++) { int new_height = height - i; if (new_height < 0) break; path[step] = i; Try(new_height, step+1); } }
-
第二章 知彼知己,百战百胜
认识常用报错类型
- 笔者总结了一下常见错误:
错误类型 常见原因 运行错误 数组越界、 无限递归(也就是“爆栈”)、库函数使用不合法 时间超限 算法效率低下、无限递推(for或者while陷入死循环)、没有正确处理调试代码 答案错误 字面意思,你懂的 - 数组越界:定义数组后没有赋初值,或者没有使用
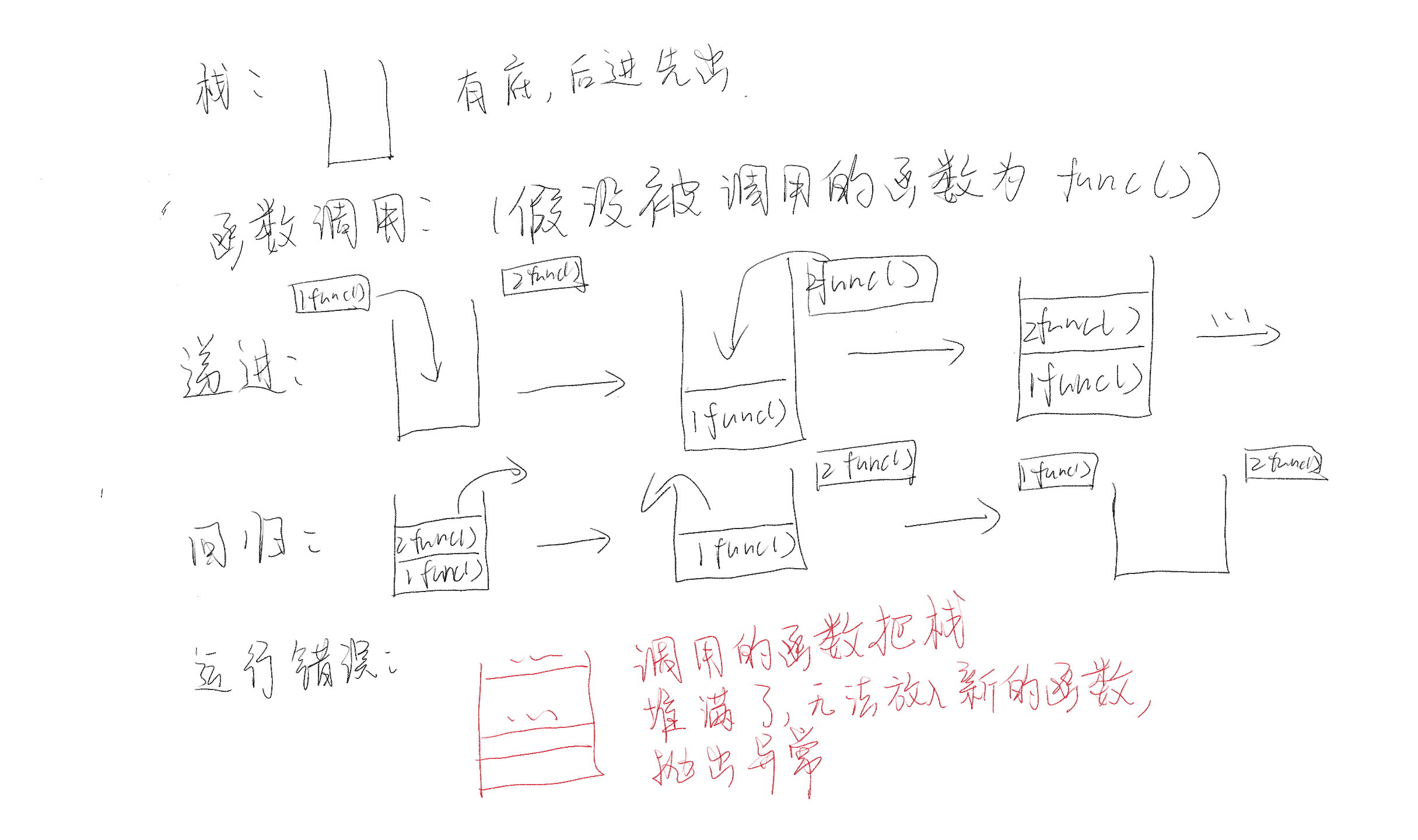
resize函数初始化数组,亦或者没有使用push_back添加元素,在这样的条件下使用中括号[]访问数组元素就触发运行错误 - 无限递归:函数调用的底层是栈。栈是一个有底的容器,具有“后进先出”的特性。栈的内存有限制,当我们不小心写了一个无限递归(即函数没有终止条件,不断调用自身),每次调都会在栈上占用新的内存。这会迅速超出栈的内存限制,也就是“超出最大递归深度”,进而抛出栈溢出异常。大家可以参考下面这张图来理解:
- 库函数使用不合法:在调用库函数的时候传入了不恰当的参数,进而导致库函数使用报错。例如,在2368. 猪猪侠大闯关中,我的一个朋友使用
stoi()来把最终结果转换为数字,却没考虑到如果最终的结果很大,超过了int能表示的最大范围,stoi()函数会报错,进而导致运行错误。 - 算法效率低下:如在动态规划问题中没有加入记忆化数组,没有剪枝、没有采用前缀和滚动数组等技巧、用DFS写BFS的题等,导致算法时间复杂度过高。
- 无限递推:不小心写了一个死循环(如
while(true)或者for循环内部对循环变量做出了更改),程序不断重复执行同一段代码而不退出,导致时间超限。由于循环递推在同一个函数内实现的,不会调用产生新的函数调用帧,所以不会报“运行错误”。 - 没有正确处理调试代码:参见本文的 3
第三章 搭建调试“实验室”
在可控条件中单步追踪可疑变量信息
- 模拟输入提高效率
- 我们在调试阶段可以自定义一个
debugger(),用于对全局变量赋初值 - 对于输入数组的题,建议编写一个新的
generate()函数(这个可以自己提前写好之后直接用) ,用于批量把输入转化为数组 - 当然,处理方法不止这一种,还可以使用
sstream和R"()"来创建多行输入流对象 - 我的
generate()函数:
template <typename T> void generate2(vector<vector<T>> &in) {
cout << "{";
for (int x = 1; x <= (int)in.size(); x++) {
cout << "{";
for (int y = 0; y < (int)in[x - 1].size(); y++) {
cout << " " << in[x - 1][y];
if (y != (int)in[x - 1].size() - 1)
cout << ",";
}
cout << "}";
if (x != (int)in.size())
cout << " ," << endl;
}
cout << "}" << endl;
}
template <typename T> void generate1(vector<T> &in) {
cout << "{";
for (int x = 1; x <= (int)in.size(); x++) {
cout << in[x - 1];
if (x != (int)in.size())
cout << ", ";
}
cout << "}" << endl;
}
- 自定义调试函数打印输出对应变量值
- 通过自定义函数,我们可以通过布尔值控制是否打印调试信息(例如本文 1-代码编写 部分,示例代码开头的全局变量
bool DEBUG),也可以实现用一行代码同时打印字符串、整数等,也可以用这个函数打印一维或二维数组,酷似python的print函数,但是又略有不同。 - 基于此。我们可以为这个
print函数套一个“过滤器”,也就是说根据关系表达式的返回值,来判断是否输出满足特定条件的信息(比如我们需要a%5==0时输出特定信息,就可以写print(a%5==0, "Message:", ...)) - 对于非递归的情况,我基于经验,根据我的需求让deepseek编写了一个通用打印函数(使用方法参见代码注释)。- 多说几句,之前也有过零星的打印一维、二维数组的函数,但后来发现每个题都要复制对应的很麻烦,而且不方便切换调试版本和提交版本。
- 以下为终版
print函数:
#include <iostream>
#include <vector>
using namespace std;
/*
使用方法:
注意:print接受的第一个参数必须是bool,用于控制是否打印!
一般在文件开始定义全局变量bool DEBUG,用于控制是否打印调试信息。
打印值:print(bool,value1,value2,value3...)
value可以是变量,也可以是字符串、整数等常量。
输出为各个value的值,相邻value用空格分隔。
示例:print(DEBUG,"tmp:",tmp);
如果tmp的值为2,则上述代码可以得到:
tmp: 2
打印容器:print(bool,vector<...>)
或 print(bool,vector<vector<...>>)
目前只支持打印一维和二维vector,并且该模式下单个print语句只能打印一个容器。
输入为向量或矩阵,输出中同行相邻元素用逗号+空格分隔,若为二维数组则多行输出。
示例:print(DEBUG,tmp);
如果tmp={{0,1},{2,1}},则输出:
0, 1
2, 1
*/
// 递归终止函数
void print_impl() { cout << endl; }
// 递归展开可变参数模板
template <typename T, typename... Args> void print_impl(T first, Args... rest) {
cout << first;
if (sizeof...(rest) > 0) {
cout << " ";
}
print_impl(rest...);
}
// 主函数模板
template <typename... Args> void print(bool should_print, Args... args) {
if (!should_print)
return;
// 使用递归展开参数包
print_impl(args...);
}
// vector 特化版本
template <typename T> void print(bool should_print, const vector<T> &vec) {
if (!should_print)
return;
for (size_t i = 0; i < vec.size(); ++i) {
cout << vec[i];
if (i < vec.size() - 1)
cout << ", ";
}
cout << endl;
}
// vector<vector> 特化版本
template <typename T>
void print(bool should_print, const vector<vector<T>> &matrix) {
if (!should_print)
return;
for (size_t i = 0; i < matrix.size(); ++i) {
for (size_t j = 0; j < matrix[i].size(); ++j) {
cout << matrix[i][j];
if (j < matrix[i].size() - 1)
cout << ", ";
}
if (i < matrix.size() - 1)
cout << endl;
}
cout << endl;
}
- 提示递归深度梳理逻辑
- 上一节介绍过,函数的调用通过栈实现,有一个“递进”和“回归”的过程。
- 这个时候,如果我们直接在函数内部使用上述方法输出调试信息,会发现很乱。我们通常调试输出函数的输入参数和结果,若不提示当前的递归深度,在看输出的时候容易看着看着就不知道这个结果对应的哪一个输入了。
- 因此,我们需要在输出信息之前,先输出空格或星号,来提示当前递归深度,让输出信息更整洁。
- 实现方法如下:
int ctrl = 1;
int example(int in) {
//计算前缀
string prefix = "";
if (DEBUG) {
for (int x = 0; x < ctrl; x++)
prefix += "*";
ctrl++;
}
print(DEBUG, prefix, "in:", in);
// 递归终止条件
if (in == 1) {
print(DEBUG, prefix, "out:", 1);
if (DEBUG)
ctrl--;
return 1;
}
// 递归计算和
int sum = example(in - 1);
sum += in;
print(DEBUG, prefix, "out:", sum);
if (DEBUG)
ctrl--;
return sum;
}
- 需要注意的有两点:一是要确保开启DEBUG的时候才计算前缀,否则提交的代码会严重超时;二是所有的
return语句前都要对ctrl做自减操作,特别是if(in == 1)这部分
- 单步模拟
- 在函数开始的时候加入
getchar()来单步模拟,对于难对付的BUG比较有用 - 该方法作用为在进入函数的时候程序中断,当用户按下任意按键,再执行函数内部代码
- 使用示例:
int example(int in) { if (DEBUG) getchar(); ... }
- 一点提醒
- 调试代码最核心的是去寻找可能有错误或者考虑不周全的逻辑。
- 因此上述调试函数等方法仅仅是为了帮助大家提高输出信息的效率;但比这更重要的是去明智地选择需要输出的变量,然后用合适的过滤器来忽略不需要打印的变量,以及通过动笔一步步验算来找到逻辑错误。盲目输出各种变量的值的行为不可取。
- 同时,对于一些比较特殊的数据结构(比如链表、集合、队列等),读者需要自己编写对应的函数来检查各种变量,以上打印函数仅供参考。
第四章 纸上演算
手动模拟调试信息中关键变量值的变化,进而发现错误
- 如果只是紧盯电脑屏幕,紧盯着调试信息不放,我们不免自己也把自己绕进程序里面去。解决复杂数学题时,我们并不是只在脑子里推演就可以把它解出来,找程序中的BUG也一样。
- 如果我们自己纸上推演一遍程序运行的结果,当输出的调试信息足够的时候,我们就会发现程序运行的误差,提升找出错误的效率
- 例题:2609. 森林冰火人
- 这是有问题的代码(不用仔细读):
int min_times(int f_x, int f_y, int i_x, int i_y, bool f_des, bool i_des) { // 阻塞递归以实现单步模拟 if (simple) getchar(); // 计算前缀 string prefix = ""; if (in_out) { for (int x = 0; x < ctrl; x++) prefix += "*"; } prefix += to_string(ctrl); ctrl++; print(in_out, prefix, "in"); check(); // 0:不可行 -1:全部达到终点 -4:走过 bool judge_f = (MAP[f_x][f_y] == 9); bool judge_i = (MAP[i_x][i_y] == 9); if (judge_f && judge_i) { print(in_out, prefix, "out: return from X"); ctrl--; // check(); f_des = 1, i_des = 1; return -1; } else if (judge_f) { f_des = 1; // 剪枝 } else if (judge_i) { i_des = 1; // 剪枝 } bool f_move = 0; bool i_move = 0; MEM[f_x][f_y][i_x][i_y] = 1; int f, i; vector<vector<vector<vector<bool>>>> mem; int mem_f_x, mem_f_y; int mem_i_x, mem_i_y; int sum = INT_MAX; int tmp; for (int x = 7; x >= 0; x--) { for (int y = 7; y >= 0; y--) { // 计算移动量 f = x % 4; i = y % 4; // 计算是否移动 f_move = x / 4; i_move = y / 4; // f_des:影响的是当前递归,判断是否达到终点 if (f_des) f_move = 0; if (i_des) i_move = 0; // 过滤器 bool filter1 = 1 && ctrl == 1; bool filter2 = 1 && ctrl == 1 && (MOVE[f][0] == 1) && (MOVE[f][1] == 0) && (MOVE[i][0] == 1) && (MOVE[i][1] == 0); bool filter3 = 1 && ctrl == 2 && (MOVE[f][0] == 0) && (MOVE[f][1] == 1) && (MOVE[i][0] == 0) && (MOVE[i][1] == -1); // maps = filter1 && 1; // validation = filter2 && 1; // 判断是否撞墙or是否走过 print(validation, prefix, "before valid:", MOVE[f][0], MOVE[f][1], MOVE[i][0], MOVE[i][1]); if (!valid(f_move, i_move, f, i)) { print(validation, prefix, "invalild!"); continue; } print(validation, prefix, "valid!"); print(in_out, prefix, "in->", MOVE[f][0], MOVE[f][1], MOVE[i][0], MOVE[i][1]); // 记忆MEM,MEM用于防止循环,由于同层级递归不同分支可以走同一个点,所以要存储当前层级递归的走过的点 mem = MEM; // 移动 mem_f_x = F_X, mem_f_y = F_Y, mem_i_x = I_X, mem_i_y = I_Y; move(f_move, i_move, f, i, sum); // 递归计算最小值 tmp = min_times(F_X, F_Y, I_X, I_Y, f_des, i_des); // 得到最小值+回溯 if (tmp == 0) { F_X = mem_f_x, F_Y = mem_f_y, I_X = mem_i_x, I_Y = mem_i_y; MEM = mem; continue; } else if (tmp == -1) tmp = 0; if (tmp > sum) break; sum = tmp + 1; // 调试区 print(_sum && filter1, sum); print(_sum && filter1, MOVE[f][0], MOVE[f][1], MOVE[i][0], MOVE[i][1]); F_X = mem_f_x, F_Y = mem_f_y, I_X = mem_i_x, I_Y = mem_i_y; MEM = mem; // 如果发现占用X则直接跳出当前递归调用,剪枝 if (f_des || i_des) x = 8, y = 8; } } if (sum == INT_MAX) { print(in_out, prefix, "out: return from fail"); ctrl--; return 0; } print(in_out, prefix, "out: return from last"); ctrl--; f_des = 0; i_des = 0; return sum; }- 这是地图:
####### #F#I### #.X.### #######- 这是调试信息输出:
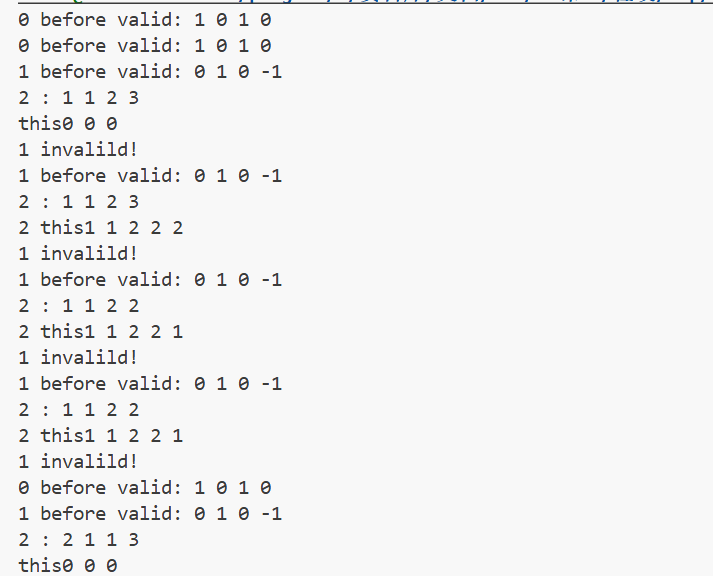
- 找到问题了吗?
- 相信现在已经迷糊了吧!没关系,当时的我也是这个状态。我们试试手动推演一下:

- 诶,为啥在第二层函数调用的时候火娃还待在(2,2)呀?(努力思考)
- 当从某个地方
return的时候,火娃依然被“粘”在终点X处。哦哦哦哦哦!也就是说,从这里退出的时候程序没有正确“回溯”! - (尝试努力检查
return相关语句)哦哦哦哦!从if (sum == INT_MAX)退出的时候,程序没有重置i_des和``f_des```! - 修改完这个BUG之后,程序就正常运行了!
第五章 使用一个“探针”
手动创造运行错误,确定错误代码位置
-
这个方法的原理是通过故意制造运行错误,对比修改前和修改后的代码各个测试点数据,观察是否有测试点数据从答案错误变为运行错误
-
这个方法相当于在某一处插入一个“探针”,去探测某一个部分的代码是否正常工作
-
为此,我编写了一个名为
dumper()的函数,用于故意制造运行错误,其原理为故意创造数组越界void dumper() { vector<int> tmp; tmp[5] = 1; } -
注:该思路更好的方法是使用
assert()断言 -
例题:2593. 语音信号处理
- 这是一道典型的可以用上述方法快速确定错误位置的题,因为这道题有明显的6个不同的状态,当出现答案错误说明其中有一些状态处理不当。我们只需要依次在进入特定状态前加入
dumper(),就可以快速定位出现问题状态对应的代码。 - 代码:
void execute() { int op = samples % 6; if (op == 0) { audiodata.erase(audiodata.begin() + 1000, audiodata.begin() + 3000); samples -= 2000; } else if (op == 1) { int y = 0; int sample = samples; for (int x = 0; x < sample; x++) { if (audiodata[y] <= 800 && audiodata[y] >= -800) { audiodata.erase(audiodata.begin() + y); samples--; y--; } y++; } } ... }- 提交上述代码之后,发现对应的“答案错误”的测试点全部变为“运行错误”,因此出错的代码
len%6==0的部分 - 自己观察代码后发现了错误:[1000,3000]一共有2001个数据点,而非2000个
- 这是一道典型的可以用上述方法快速确定错误位置的题,因为这道题有明显的6个不同的状态,当出现答案错误说明其中有一些状态处理不当。我们只需要依次在进入特定状态前加入
-
该方法也有一种变式,就是故意制造答案错误(通常是先输出,然后提前
return),从而用二分法来找到出现“运行错误”的代码片段
因时间有限,本文的校对工作难免存在疏漏。若您在阅读时发现任何问题,恳请通过微信或邮箱(ykx25@mails.tsinghua.edu.cn)与我联系。感谢您的理解与帮助!
Comments 3 条评论
/拜谢
@yx
